
Bestimmt hast du bereits schon einmal von dieser Datei gehört. Doch was genau verbirgt sich eigentlich hinter der robots.txt-Datei? Wie funktioniert sie und welche Auswirkungen hat sie auf deine Website?
Wir verraten es dir!
robots.txt – was ist das?
Bei einer robots.txt-Datei handelt es sich um eine Textdatei. Diese ist eine Art Anleitung für Bots und Crawler (z.B. Googlebot), in der steht, welche Verzeichnisse einer Website gelesen werden dürfen und welche nicht. So können zum Beispiel auch doppelte Dateien von der Indexierung ausgeschlossen werden.
Ohne eine solche robots.txt-Datei durchsucht der Crawler oder Bot die gesamte Website – potenziell jede einzelne Datei. Diese können dann alle etwa in der Google Suche landen, auch wenn sie dort gar nicht landen sollten (z.B. privater Admin-Bereich der Website). Das kann auch negative Auswirkungen auf deine Suchmaschinenoptimierung haben, da Unterseiten durchsucht werden, die nicht für Suchmaschinen optimiert sind.
Beispiel für eine robots.txt-Datei
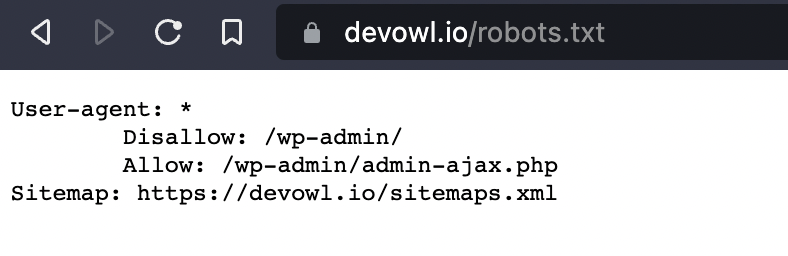
In dem Screenshot siehst du die txt-Datei der devowl.io-Website. Im Folgenden dröseln wir den Aufbau der robots.txt-Datei einmal auf.
User-agent: *:Hier wird festgelegt, welche Bots und Crawler die Website durchsuchen dürfen. Das Sternchen (*) bedeutet, dass sämtliche Bots/Crawler Zugriff haben. Alternativ könnte hier auchUser-agent:Googlebot stehen, damit ausschließlich der Google Bot die Website durchsucht.Disallow: /wp-admin/:In Disallow legst du fest, welche Verzeichnisse, Seiten und Dateien nicht von denen im User-agent festgelegten Bots/Crawlern ausgelesen werden dürfen. In unserem Fall handelt es sich um Seiten, die mit devowl.io/wp-admin/ beginnen – sprich dem Admin-Login. Sollte anstelle von/wp-admin/einfach nur/stehen würde das bedeuten, dass kein Verzeichnis durchsucht werden darf. Das heißt, Bots würden die Website gar nicht durchsuchen. Trägst du hinterDisallow:nichts ein, werden alle Seiten gecrawlt.Allow: /wp-admin/admin-ajax.php:Alle Bots dürfen die konkrete PHP-Datei durchsuchen. Auch hier gilt wieder, dass der Seitenname dem im Browser angezeigten entsprechen muss.Sitemap: https://devowl.io/sitemaps.xml:In manchen Fällen – wie bei uns – findest du auch einen Sitemap-Eintrag in derrobots.txt-Datei. Dieser Eintrag verrät dir, wo genau du die Sitemap der entsprechenden Website findest. Den Link kannst du kopieren und in einem neuen Tab einfügen. In einer XML-Sitemap sind alle URLs einer Website aufgelistet.
Reguläre Ausdrücke in der robots.txt
Manchmal ist es unpraktisch, immer die vollständigen Verzeichnis-, Seiten- oder Dateinamen anzugeben. Zum Beispiel, wenn du alle .pdf Dateien in allen Unterverzeichnissen vom Crawlen ausschließen möchtest. Daher gibt es reguläre Ausdrücke – dynamische Regeln – die du verwenden kannst.
*: Das*-Symbol – auch als Wildcard bekannt – kommt zum Einsatz, wenn du beliebige Zeichen innerhalb einer Zeichenkette haben möchtest. Zum Beispiel, indisallow: /uploads/product/*/*.jpgwerden alle JPG-Bilder (zweites Sternchen für den Bildnamen), die in einem Unterverzeichnis (erstes Sternchen) von uploads/product/ stecken, nicht mehr gecrawlt.$: Außerdem gibt es noch das Dollar-Zeichen. Dieses kommt zusätzlich zum Wildcard-Symbol zum Einsatz, wenn du URLs ausschließen möchtest, die eine bestimmte Endung haben. Beispielsweisedisallow: *.pdf$sagt aus, dass alle.pdf-Dateien nicht gecrawlt werden sollen.
Crawl-Delay: Entscheide, wie schnell der Crawler arbeitet!
Die Crawl-Delay gibt an, mit welcher Verzögerung in Sekunden der Bot die Seiten crawlen soll. Crawl-Delay: 10 bedeutet, dass der Bot Crawling-Vorgänge jeweils in einem Abstand pro Datei/Seite von 10 Sekunden durchgeführt werden soll.
Wie sieht eine komplexe robots.txt-Datei aus
Theoretisch kannst du deine robots.txt-Datei auch ausweiten und mehrere Einträge aufnehmen. Das könnte dann etwa so aussehen:
User-Agent: GooglebotDisallow: /*.pdf$ User-Agent: Adsbot-Google Disallow: / User-Agent: * Disallow: /wp-admin/
In diesem Beispiel geschieht Folgendes:
- Google Bot: Darf alles crawlen, außer
.pdf-Dateien. - Google Ads Bot: Darf die Website gar nicht crawlen.
- Alle anderen Bots: Dürfen die gesamte Website crawlen, außer das
/wp-admin/-Verzeichnis.
Wo finde ich die robots.text-Datei meiner Website?
Die robots.txt-Datei befindet sich im Stammverzeichnis – auch Root-Verzeichnis genannt – deiner Website. Die Datei kannst du aufrufen, indem du in deinem Browser die Domain der Website mit dem Zusatz /robots.txt aufrufst. Beispiel:devowl.io/robots.txt
Genauso findest du die robots.txt Datei im Stammverzeichnis, wenn du dich per FTP mit deinem Webspace verbindest.
Möchte ein Webcrawler oder Bot deine Website durchsuchen, ist die robots.txt-Datei im Stammverzeichnis dessen erste Anlaufstelle. Nachdem er weiß, was er überhaupt crawlen darf, durchsucht er die Website erst weiter.
Wie kann ich eine robots.txt-Datei erstellen?
Um eine robots.txt-Datei ohne viel Mühe zu kreieren, gibt es mittlerweile einige Tools, die du zur Hilfe nehmen kannst. Eines dieser Tools ist der robots.txt-Generator von ryte.
Der robots.txt-Generator ist sehr anfängerfreundlich aufgebaut. Du kannst dir deine robots.txt-Datei in wenigen Schritten zusammenschustern. Nachdem du alles eingestellt hast, drückst du auf erstellen und kannst die fertige Datei herunterladen. Diese musst du dann nur noch z.B. via FTP in das Stammverzeichnis deiner Website hochladen.
Eine weitere Möglichkeit ist der robots.text-Generator von SEO-Ulm.
Auch dieser Generator ist ähnlich wie der von ryte aufgebaut. Du kannst unterschiedliche Einstellungen vornehmen – wie die verschiedenen Bots festlegen. Im Anschluss kannst du die Datei erstellen und herunterladen.
Wie kann ich die robots.txt hochladen?
Wenn du keine Lust hast, die robots.txt-Datei mittels FTP-Client (z.B. Filezilla) hochzuladen, bleiben dir zwei weitere Optionen: Entweder du wendest dich an deinen Hosting-Anbieter (wenn du keinen direkten Zugriff auf den Webserver hast) oder du verwendest ein WordPress-Plugin. Eines dieser Plugins ist WP Robots Txt.
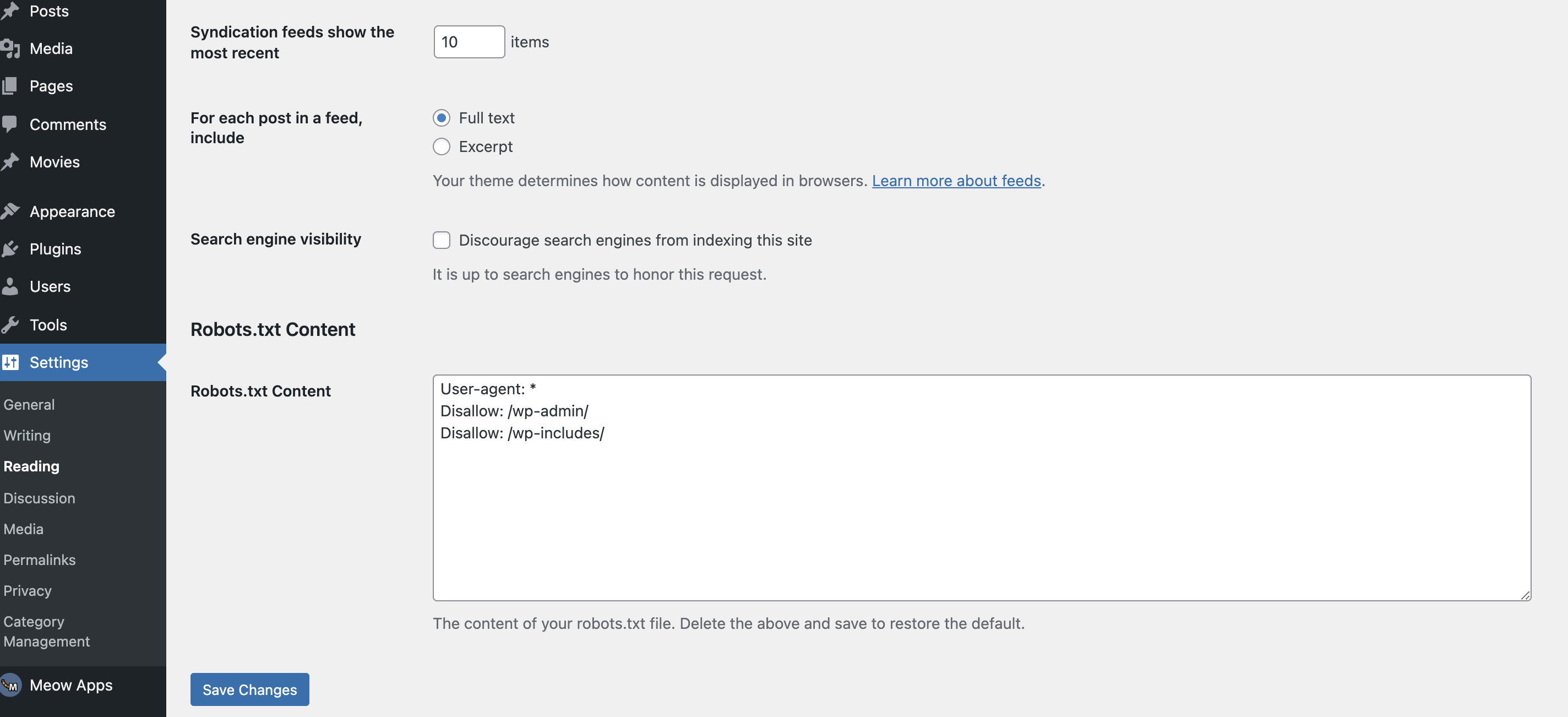
Das Plugin ist kostenlos. Nach der Installation findest du es links in der Menüleiste unter Einstellungen > Lesen. Scrollst du hier nach unten, findest du nun den Eintrag Robots.txt Content. Hier kannst du in WordPress die robots.txt-Datei bearbeiten. In das entsprechende Feld kannst du den Code eintragen, den wir im vorherigen Schritt generiert haben. Vergiss nicht, die Änderungen im Anschluss abzuspeichern.
Aber auch mithilfe des Yoast SEO-Plugins kannst du eine robots.txt-Datei hinzufügen.
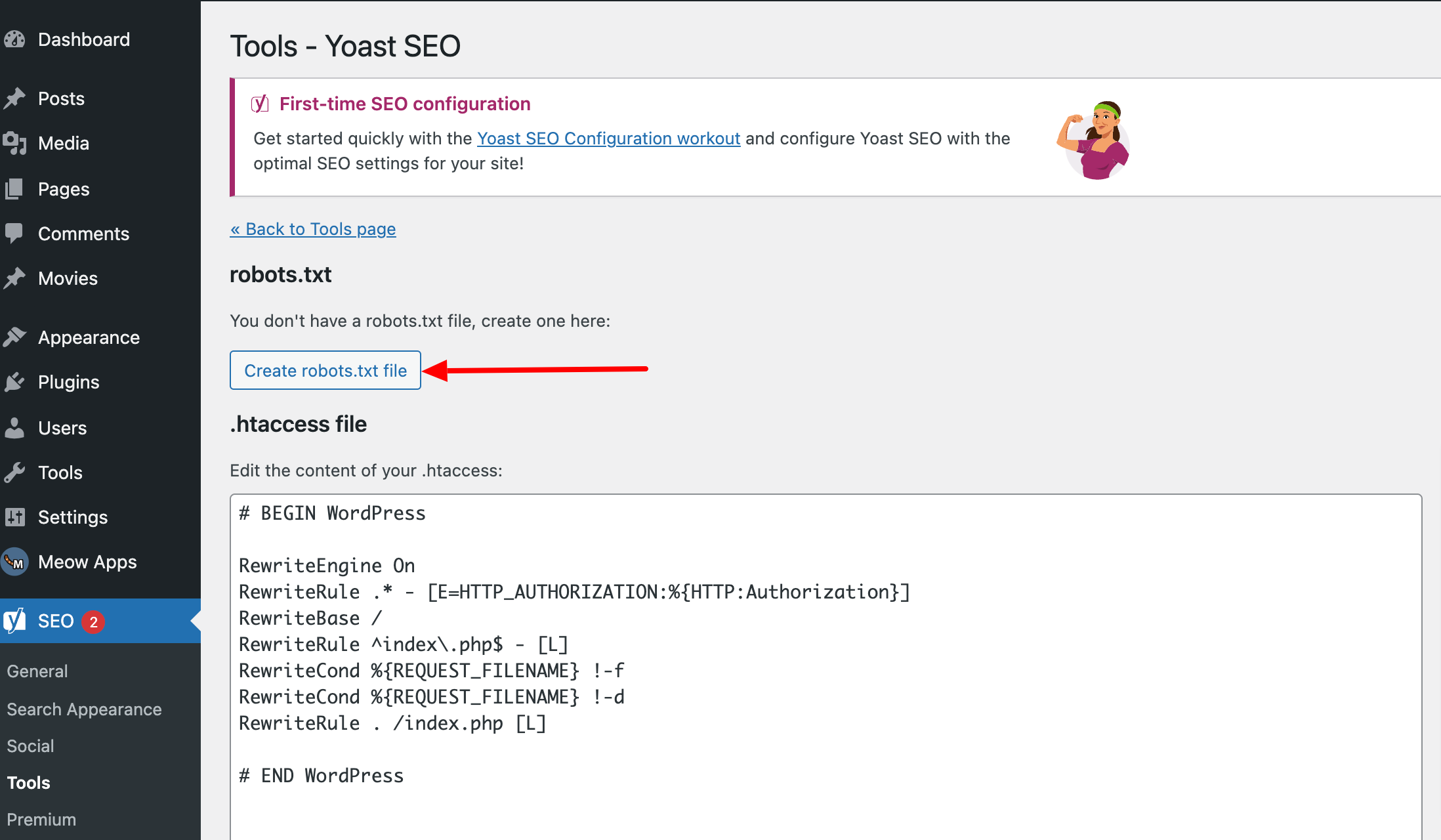
Um deine erstellte robots.txt-Datei zu importieren, gehst du nach der Installation links im Menü auf Werkzeuge > Datei-Editor. Hier findest du die Option, die Datei hochzuladen.
robots.txt und SEO
Was hat die robots.txt-Datei eigentlich mit der Suchmaschinenoptimierung zu tun? Nicht gerade wenig. Mittels der robots.txt-Datei kannst du grundsätzlich besser steuern, welche Seiten von den Bots gecrawlt und indexiert werden sollen. Das spart nicht nur Google beim Crawlen Zeit, sondern trägt dazu ein, dass nur relevante Seiten deiner Website in Google landen. Dies kann positiven Einfluss auf deine Platzierung im Google-Ranking haben.